What is a data plan, and why is it important to have one?
"Wait, why do we need this data again?" "Was that attribute supposed to use snake or camel case?" Data tracking plans keep everyone in your organization aligned on your data efforts, from the high-level strategy to the nittiest, grittiest details.


(Already sold on data plans? Get started with this data plan template)
What is a data plan?
A data tracking plan is a document that keeps different teams aligned on the key information regarding your organization’s data collection and analysis efforts. It includes information like specific user events collected, conventions for naming and organizing that data, the business goals that each data point serves, and other details.
It is an internal framework that spells out (among other things):
- Which user events will be tracked?
- Where will you track user events?
- What names will you give to specific events/event categories?
- How will you name your event data attributes?
- Which data types (strings, integers, booleans, enums, etc.) will you use as event values?
- What role will each user event play in your data analysis strategy?
A data tracking plan can exist as a static document like a spreadsheet, or it can live within a data software solution like a Customer Data Platform (CDP). For tips on how to create a data tracking plan, check out this great guest blog post from Glenn Vanderlinden, Strategy Lead at Human37.


What purpose does a data plan serve?
When you launch a new product, it is easy to grow a base of adoring users. Once people start flocking to your app or website, they intuitively understand the paths they need to follow to accomplish what they want––no A/B testing, journey mapping, or analysis of any kind will be required. Undoubtedly, your product’s earliest fans will vehemently sing its praises to their friends, family, and coworkers. Your users will grow by an order of magnitude each month, at which point you will understand with perfect clarity how to meet the needs of everyone within this ballooning base of customers.
These statements, of course, are lies.
None of these things happen automatically. Acquiring new users requires understanding user engagements and gaining insights from activity. This relies on:
- Well-executed data collection informed by a smart data plan, and
- Cohesion between the teams that create this plan (Marketing, Product Management) and those that implement it (Engineering) to allow cross-organization access to insights.
What do customer data tracking plans have to do with engineers?
Typically, it’s Marketing, Product Management, and Data Engineers that are most involved in decisions around the data tracking plan, but these are by no means the only internal stakeholders who need to stay in sync with this information. Data tracking plans are only meaningful if they are correctly implemented in your production code, and doing this falls squarely on the shoulders of one team: Engineering.
Without developers implementing tracking code, a data tracking plan is just another document. Additionally, if developers make a mistake and collect the wrong data––say, by using an incorrect attribute name or data type––inaccurate data will find its way into the internal pipeline, potentially resulting in misguided analysis and decision-making. What’s more, errors in your data pipeline can erode trust in your data collection efforts, leading internal teams to shy away from leveraging data to make decisions altogether.
At the very least, bad data making its way to downstream systems will require potentially time-consuming debugging on the part of engineering teams. This diverts time away from building the core features that drive value for your business, and tedious work like this tends to be a morale killer for developers.
Learn how to identify and debug customer data errors in real time, before they become a problem.
Bridge the gap between data plans and source code
As data tracking plans grow and evolve, relying on engineers to manually implement changes and manage data quality quickly becomes untenable. One of the most significant advantages of infrastructure CDPs is that they give cross-functional teams the ability to create data plans inside of a UI, and use this as the single source of truth throughout the organization. In mParticle, for instance, once a Data Plan has been created, developers have the tools to programmatically import data tracking plans into the codebase, and use this to enforce data quality throughout event instrumentation.
This is exactly what mParticle’s Smartype, a code generation tool built on Kotlin multiplatform, is built to do. Smartype automatically translates any data model built on JSON schema––not only those imported from mParticle––into libraries usable in Web, iOS, and Android projects.
In other words, it changes this:
{
"properties":{
"quantity":{
"type":"number"
},
"milk":{
"type":"boolean"
},
"item":{
"enum":[
"cortado",
"espresso",
"regular_coffee"
],
"type":"string"
}
}
}...into this:
val coffee = CoffeeOrder(
quantity = 5.0,
milk = true,
item = CoffeeOrderItem.CORTADO
)
api.send(coffee)...when you run this: smartype generate
Even if you’re not working with mParticle, you can still leverage Smartype in your projects to automatically generate data collection code. Take a look at the Smartype Github repo and documentation to learn more about how to get started.
Additionally, engineering teams working with mParticle can also use the Data Planning Snippet SDK to help streamline data collection implementation and avoid errors in the process. This SDK ingests a Data Point (an umbrella term for a unit of data collected with mParticle’s SDKs and APIs) from your Data Plan, and translates it into executable code, again covering its bases as far as usage environments––iOS (both Swift and Objective-C), Android (Kotlin and Java), and Web (JavaScript) are all supported.
The Data Planning Snippet also exposes an interface in which you can copy-paste your data plan and generate event collection code:
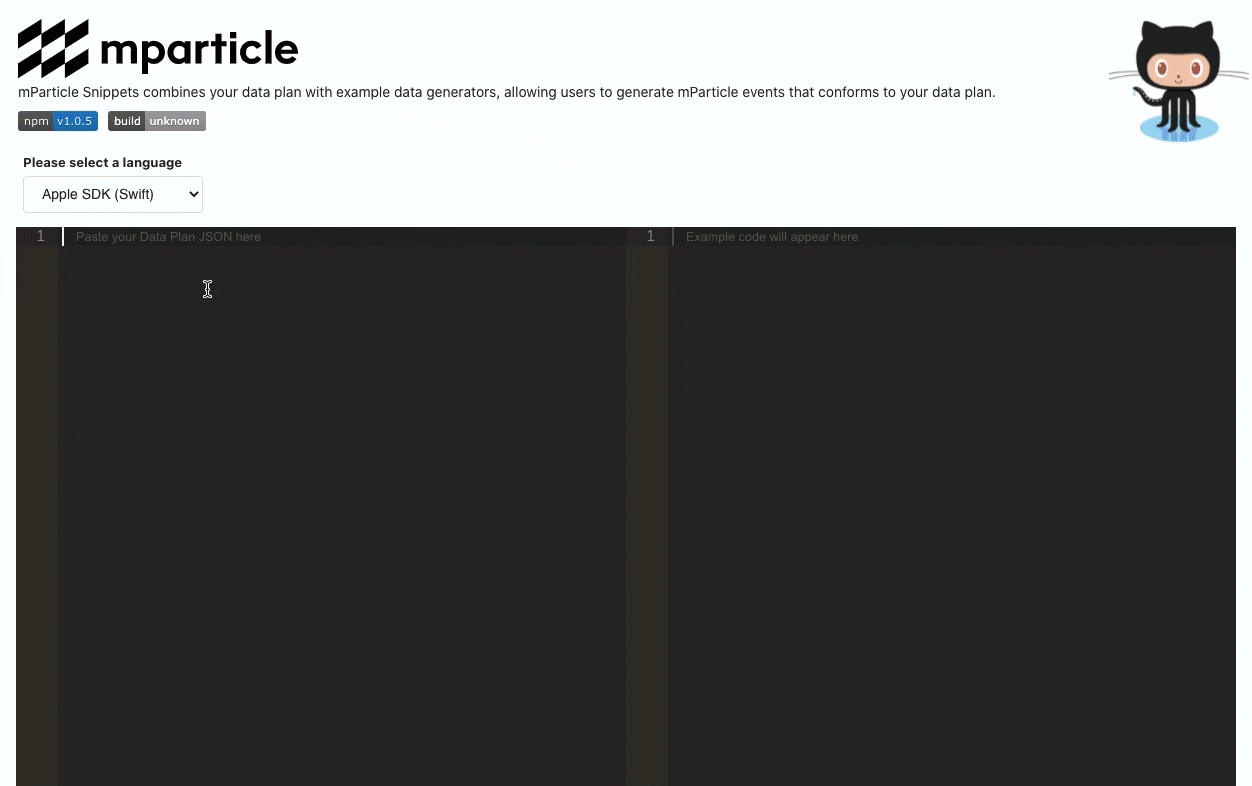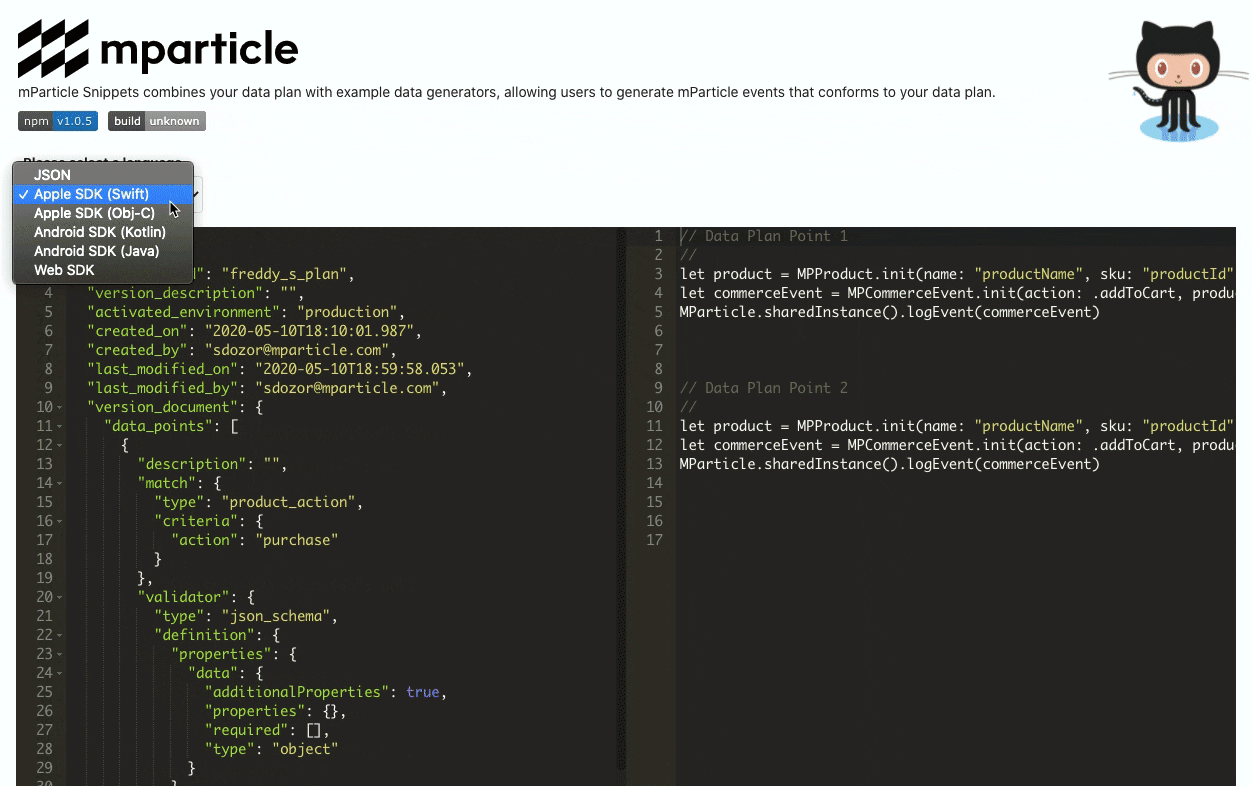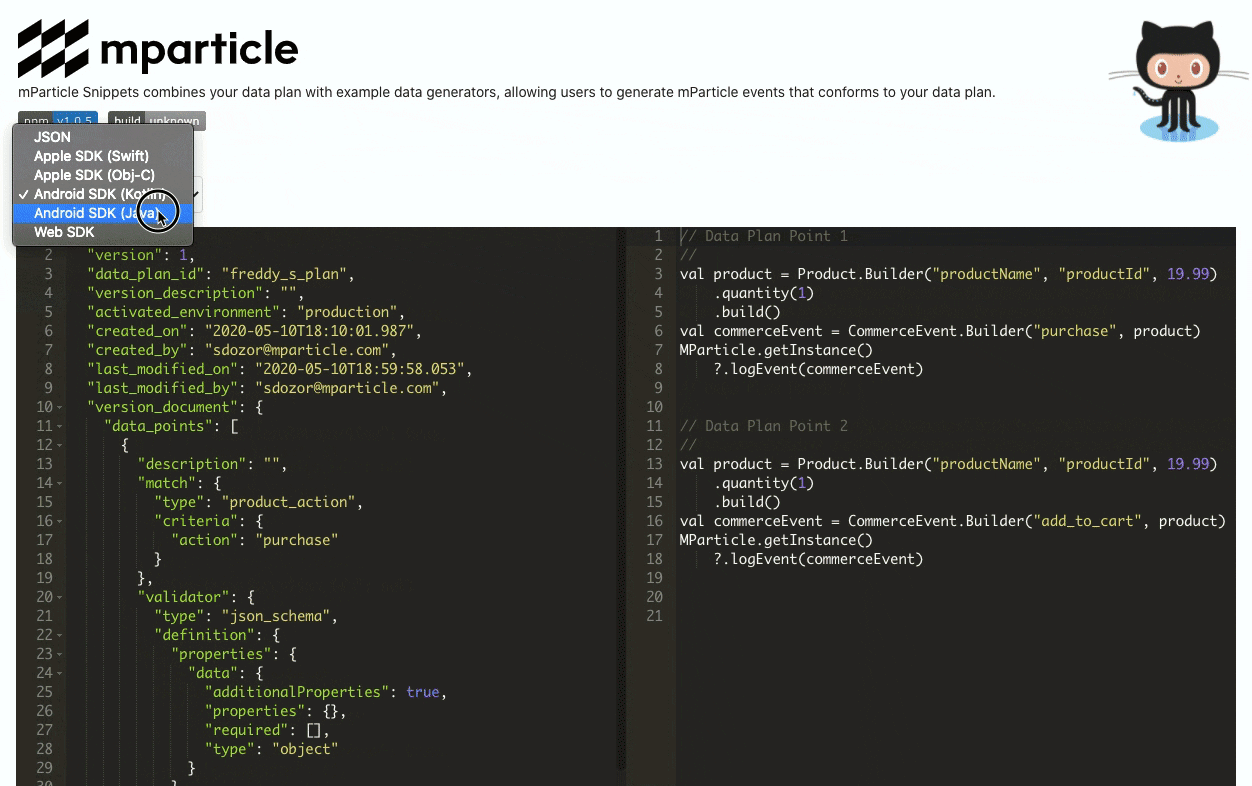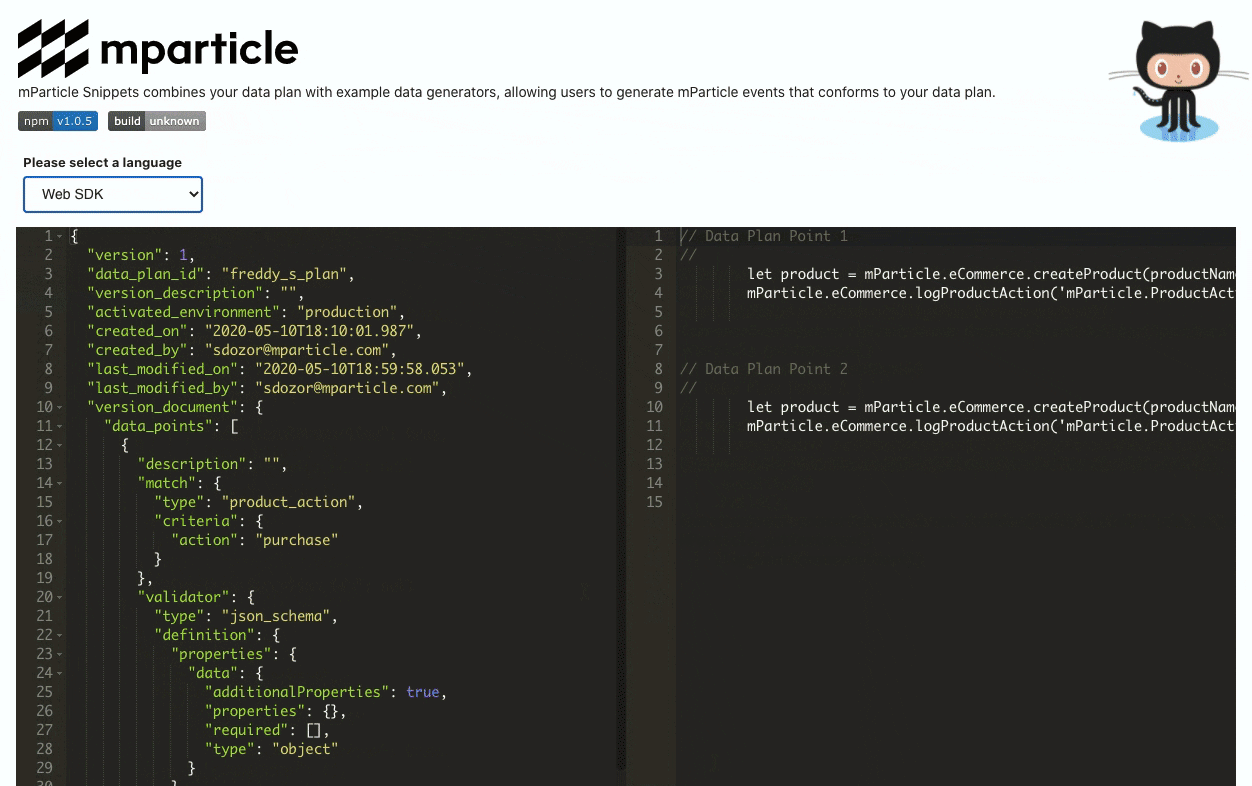
Next step: Create, implement, and QA a data plan in real time with mParticle
Here we learned the basics of data tracking plans, and saw how mParticle Data Plans take this concept further by enabling a seamless connection between the growth teams that define this plan, and the engineers responsible for implementing it. In the next part of this series, we will see what it looks like to create a data plan inside mParticle, instrument it in a sample application, see real time data entering mParticle in real time, and use mParticle’s data Live Stream to spot and correct errors as they arise.






